

Several software packages estimate the carbon emissions of AI workloads. Recently a team at Université Paris-Saclay tested a group of these tools to see if they were reliable. “And they’re not reliable at all,” says Anne-Laure Ligozat, a co-author of that study who was not involved in the new work.
The new approach differs in two respects, says Jesse Dodge, a research scientist at the Allen Institute for AI and the lead author of the new paper, which he presented this week at the ACM Conference on Fairness, Accountability, and Transparency (FAccT). First, it records server chips’ energy usage as a series of measurements, rather than summing their use over the course of training. Second, it aligns this usage data with a series of data points indicating the local emissions per kilowatt-hour (kWh) of energy used. This number also changes continually. “Previous work doesn’t capture a lot of the nuance there,” Dodge says.
The new tool is more sophisticated than older ones but still tracks only some of the energy used in training models. In a preliminary experiment, the team found that a server’s GPUs used 74% of its energy. CPUs and memory used a minority, and they support many workloads simultaneously, so the team focused on GPU usage. They also didn’t measure the energy used to build the computing equipment, or to cool the data center, or to build it and transport engineers to and from the facility. Or the energy used to collect data or run trained models. But the tool provides some guidance on ways to reduce emissions during training.
“What I hope is that the vital first step towards a more green future and more equitable future is transparent reporting,” Dodge says. “Because you can’t improve what you can’t measure.”
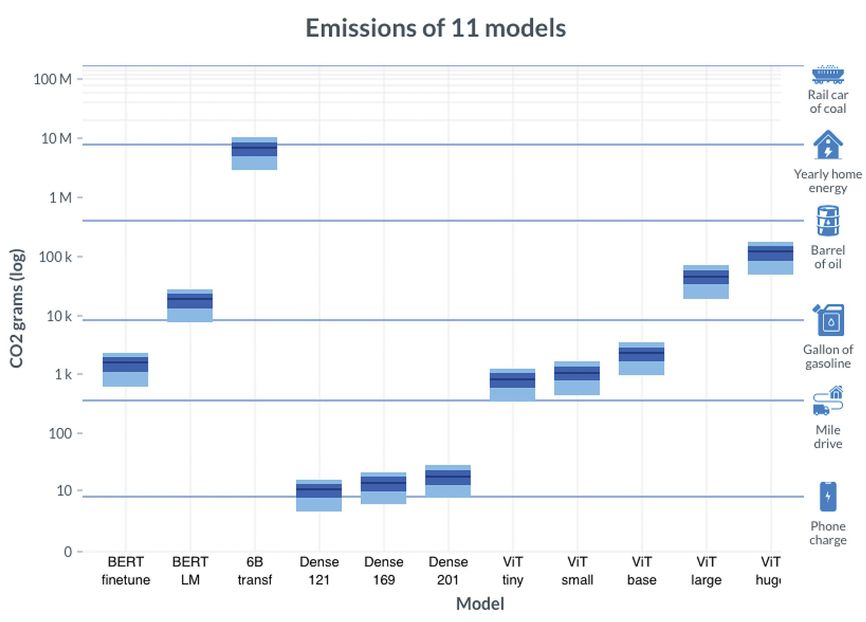
The researchers trained 11 machine-learning models of different sizes to process language or images. Training ranged from an hour on one GPU to eight days on 256 GPUs. They recorded energy used every second or so. They also obtained, for 16 geographical regions, carbon emissions per kWh of energy used throughout 2020, at five-minute granularity. Then they could compare emissions from running different models in different regions at different times.
Powering the GPUs to train the smallest models emitted about as much carbon as charging a phone. The largest model contained six billion parameters, a measure of its size. While training it only to 13% completion, GPUs emitted almost as much carbon as does powering a home for a year. Meanwhile, some deployed models, such as OpenAI’s GPT-3, contain more than 100 billion parameters.
The biggest measured factor in reducing emissions was geographical region: Grams of CO2 per kWh ranged from 200 to 755. Besides changing location, the researchers tested two CO2-reduction techniques, allowed by their temporally fine-grained data. The first, Flexible Start, could delay training up to 24 hours. For the largest model, which required several days of training, delaying it up to a day typically reduced emissions less than 1%, but for a much smaller model, such a delay could save 10–80%. The second, Pause and Resume, could pause training at times of high emissions, as long as overall training time didn’t more than double. This method benefited the small model only a few percent, but in half the regions it benefited the largest model 10–30%. Emissions per kWh fluctuate over time in part because, lacking sufficient energy storage, grids must sometimes rely on dirty power sources when intermittent clean sources such as wind and solar can’t meet demand.
Ligozat found these optimization techniques the most interesting part of the paper. But they were based on retrospective data. Dodge says in the future, he’d like to be able to predict emissions per kWh so as to implement them in real time. Ligozat offers another way to reduce emissions: “The first good practice is just to think before running an experiment,” she says. “Be sure that you really need machine learning for your problem.”
Microsoft, whose researchers collaborated on the paper, has already implemented the CO2 metric into its Azure cloud service. Given such information, users might decide to train at different times or in different places, buy carbon offsets, or train a different model or no model at all. “What I hope is that the vital first step towards a more green future and more equitable future is transparent reporting,” Dodge says. “Because you can’t improve what you can’t measure.”





